Descripción
Introducción
El procesamiento del Lenguaje Natural (PLN) es una parte esencial de la Inteligencia Artificial que investiga y formula mecanismos computacionalmente efectivos que faciliten la interacción hombre/máquina y permitan una comunicación mucho más fluida y menos rígida que los lenguajes formales. Los sistemas que incluyen técnicas de PLN intentan simular el comportamiento lingüístico humano; para ello deben tomar conciencia tanto de las estructuras propias del lenguaje, como del conocimiento general acerca del universo del discurso. En este sentido, el "Taller Internacional de Lingüística Computacional, hacia el análisis profundo de documentos digitales" busca proporcionar a los asistentes una introducción al Procesamiento del Lenguaje Natural, Aprendizaje Automático, Aprendizaje Profundo (Deep Learning), haciendo énfasis en las bases teóricas necesarias para atacar problemas relacionados con el análisis automático de documentos digitales.
El presente taller es continuación directa de los esfuerzos realizados en años previos por la Red Temática en tecnologías del Lenguaje (RedTTL), cuyo objetivo principal ha sido dar a conocer a la comunidad los temás más relevantes y recientes al rededor de las Tecnologías del Lenguaje Humano.
Audiencia
El taller está dirigido a estudiantes de nivel superior y de posgrado con interés en conocer técnicas recientes de procesamiento de lenguaje natural, deep learning, así como en las aplicaciones y retos recientes que se pueden abordar empleando estos coceptos.
Principalmente dirigido a:
- Estudiantes en su último año de carrera, preferentemente con fomación de Computación o áreas afines
- Estudiantes de posgrado con intereses en el desarrollo de métodos automáticos para el análisis del lengauje
Objetivo General
El lenguaje humano es el medio de comunicación existente más eficaz, y a su vez el más complejo. Uno de los retos a resolver en esta era de la información y del conocimiento es el tratamiento automático del lenguaje. El objetivo general de este taller es proporcionar a los asistentes una introducción, intensiva y accesible, a la Inteligencia Artificial, a la Lingüística Computacional y a las herramientas relacionadas existentes actualmente. Usar de forma apropiada estos conceptos representan un nicho de oportunidad para el desarrollo de trabajos multidisciplinarios de alto impacto.
Dinámica del Taller
Los diferentes tutoriales que serán impartidos en el taller representan un material altamente práctico. Las dinámicas del curso están pensada para que los asistentes aprendan de manera práctica por medio de ejemplos y ejercicios resueltos. Hacia el final del taller se planteará a los asistentes un reto actual de PLN, para el cual podrán proponer estrategias de solución empleando los conceptos vistos en los distintos tutoriales.
Solicitud de registro
El taller es un evento público y sin costo, sin embargo tiene un cupo limitado. Por esta razón se dará preferencia a aquellos estudiantes cuyos temas de tesis estén relacionados directamente con el área de PLN y que además sean miembros de la RedTTL; o en su defecto, a aquellos estudiantes que estén trabajando con algún investigador miembro de la RedTTL.
Para indicar que quieres participar en el #TallerPLN2018 debes llenar el siguiente formulario (Registro cerrado). Revisaremos tu solicitud, y te notificaremos vía correo electrónico si has sido aceptado a participar en el taller.
Fechas importantes
El TallerNLP2018 se realizará los días 20, 21 y 22 de Junio del 2018 en las Instalaciones de la UAM Cuajimapla.
Cómo llegar
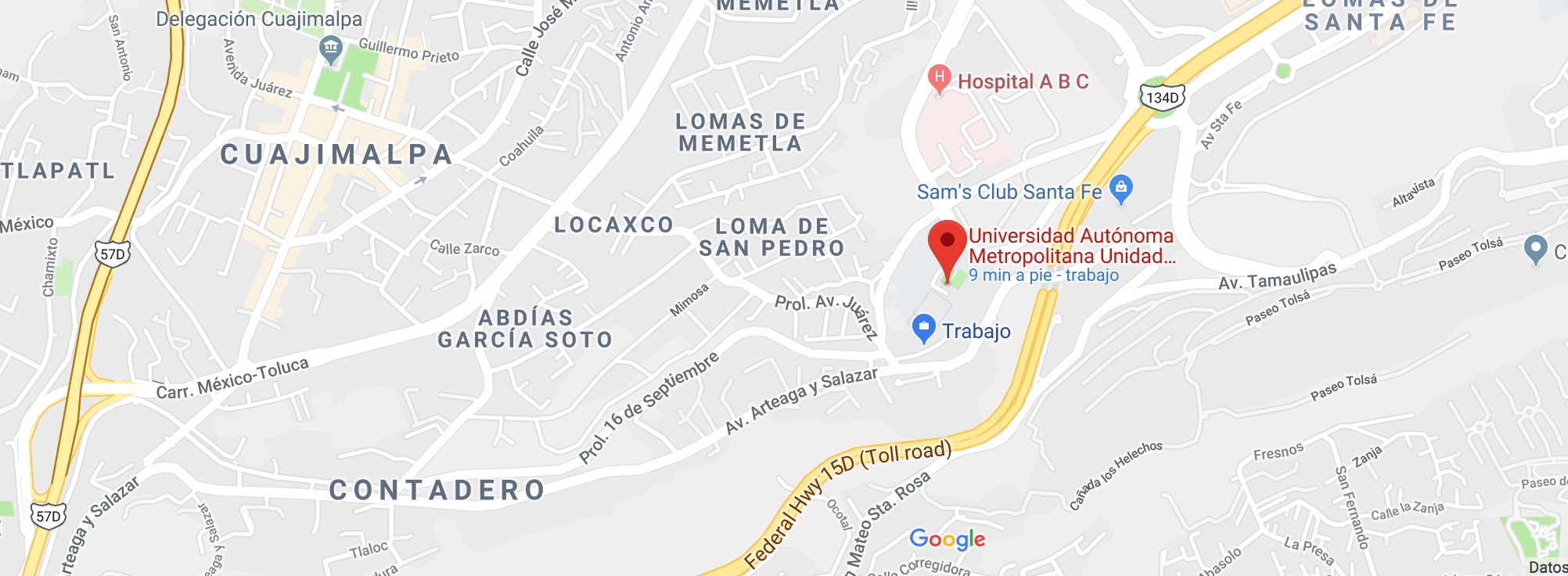
Dirección:
Av. Vasco de Quiroga 4871, Colonia Santa Fe Cuajimalpa, Delegación Cuajimalpa de Morelos, México, Distrito Federal, C.P. 05300.
Rutas de llegada:
Programa
Programa General
Todas las actividades se realizarán en la Sala de Consejo Académico de la UAM Cuajimalpa, ubicadas en el 8º piso.
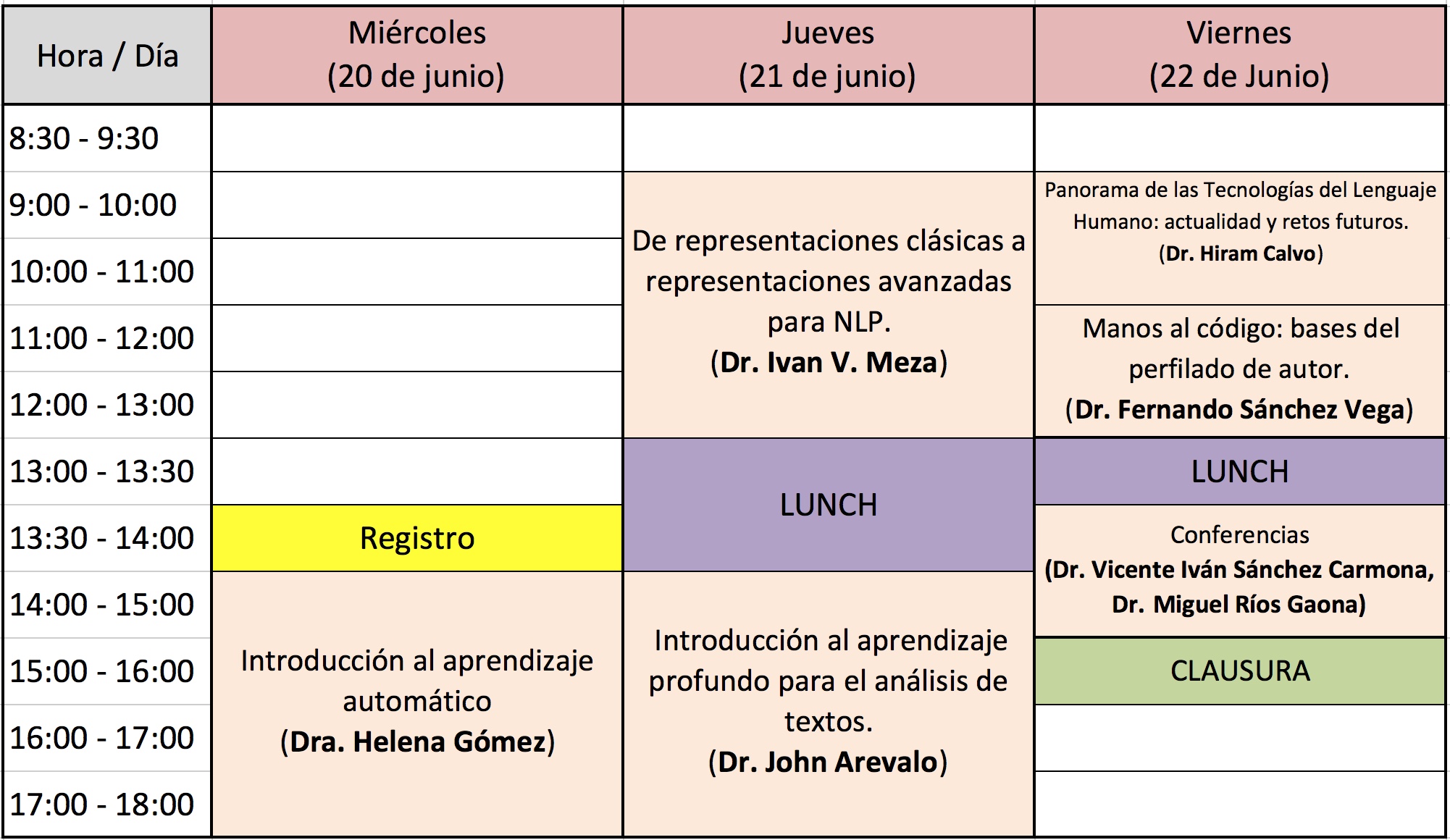
Miércoles 20 de Junio - 14:00 a 18:00hrs
Introducción al aprendizaje automático (Dra. Helena Gómez Adorno / UNAM)
Objetivo:
Comprender los conceptos básicos de Aprendizaje Automático y el flujo de trabajo. Cómo aplicar correctamente el aprendizaje automático componentes y características (como caja negra). Ventajas y desventajas de diferentes algoritmos de clasificación. Aprender a aplicar algoritmos de aprendizaje automático en Python usando el paquete scikit-learn.
Contenido:
- Fundamentos del aprendizaje automático: introducción a SciKit Learn
-
Conceptos básicos de aprendizaje automático
-
Tareas y flujo de trabajo usando un problema de clasificación de ejemplo usando el método de k- vecinos más cercanos.
- Herramientas de Python para aprendizaje automático: Implementación de ejemplo usando la biblioteca scikit-learn
-
- Clasificación supervisada: Clasificación y Regresión
-
Complejidad del modelo: Generalización, overfitting y underfitting
-
Máquinas de vectores de soporte
-
Árboles de desición
-
Clasificadores Bayesianos
-
Validación cruzada para la evaluación del modelo
-
- Evaluación: Cómo optimizar un modelo de aprendizaje automático
-
Métricas de evaluación
-
Matriz de confusión
-
Funciones de decisión
-
Selección del modelo
-
Requerimientos:
- Python 3, jupyter notebook, scikit-learn 0.17.1, scipy 0.17.1, numpy 1.11.1, pandas 0.18.1, matplotlib 2.0.0, seaborn 0.7.1, graphviz 0.7.0
Materiales disponibles:
Jueves 21 de Junio - 9:00 a 13:00hrs
De repesentaciones clásicas a representaciones avanzadas para NLP (Dr. Ivan V. Meza Ruiz / IIMAS)
Objetivo:
Que el alumno se familiarice con los distintos tipos de representación tradicionales dentro del área de Procesamiento de Lenguaje Natural. Dar a conocer representaciones semánticas, y las ventajas de estas sobre las Bolsas de Palabras.
Contenido:
- Introducción a representaciones de texto para NLP
- Técnicas de preprocesamiento de texto
- Características.
- Represetacioes: ngramas, esquemas de pesado, bolsa de palabras, LIWC, LDA, Matrix Factorization, GLOVE, word2vec
Requerimientos:
- PC, con Linux preferentemente o con Python Acanonda.
Modalidad:
- Teórico-Práctica
Materiales disponibles:
- Diapositivas (http://turing.iimas.unam.mx/~ivanvladimir/slides/nlp/presenentations_taller_nlp_uam.html) (PDF)
- Notebook ( https://gitlab.com/ivanvladimir/nlp_notebooks/tree/master) o para clonar el código:
git clone git@gitlab.com:ivanvladimir/nlp_notebooks.git
Jueves 21 de Junio - 14:00 a 18hrs
Introducción al aprendizaje profundo para el análisis de textos (Dr. John Arevalo / UNAL-Colombia)
Objetivo: Introducir a las redes neuronales profundas y sus aplicaciones en el análisis y comprensión de textos.
Contenido:
- Introducción a las redes neuronales
- Breve historia
- Definición de redes neuronales
- Entrenamiento
- Aprendizaje de la representación
- Redes convolucionales
- Redes recurrentes
- Arquitecturas para análisis de texto
- Clasificación
- Modelos de lenguaje
- Neural Machine Translation
Requerimientos:
- Imagen de Docker (Instrucciones)
- Diapositivas
- Video de la sesion
Modalidad:
- Teórico / Práctica
Viernes 22 de Junio - 9:00 a 10:00hrs
Panorama de las tecnologías del lenguaje humano: actualidad y retos futuros (Dr. Hiram Calvo / CIC-IPN)
Viernes 22 de Junio - 10:00 a 13:00hrs
Manos al código: bases del perfilado de autor (Dr. Fernando Sánchez-Vega / RedTTL-CONACyT)
Objetivo:
Introducir a los asistentes en los mecanismos de desarrollo de las tecnologías del lenguaje natural. Motivar a los asistentes a proponer e innovar en el área del procesamiento del lenguaje natura. Introducir la tarea del perfilado de autor y codificar los principales métodos del estado del arte.
Contenido:
- Introducción a la tarea perfilado del autor en redes sociales
- Revisión del corpus mexicano: Authorship Attribution in Twitter Mex-A3T
- Generación del pipeline básico para evaluación
- #Live_coding 1: Métodos del estado del arte
- Basados en palabras: BoW y Lexicones
- Basados en modelos de lenguaje: n-grams, skip-n-grams
- #Live_coding 2: Selección y transformación de atributos:
- Aplicación de selección de atributos
- Transformación de atributos: generación de representaciones
- #BrainStorm: Discusión de nuevas ideas
- Camino metodológico y prueba de hipótesis
- Programa de mentoría
Requerimientos:
- Conocimientos de programación en Python
- Preinstalación de Python 2.7, jupyter notebook, scipy 0.17.1, numpy 1.11.1, scikit-learn 0.17.1, nltk 3.3
- Corpus AP-MEXA3T (Descargar!)
- Para descargar
- Video de la sesion
Viernes 22 de Junio - 13:30 a 14:30hrs
Análisis del comportamiento de modelos de inferencia de lenguaje natural: Una evaluación de robustez. (Dr. Vicente Iván Sánchez Carmona /Universidad de College London).
Abstract: Natural Language Inference is a challenging task that has received substantial attention, and state-of-the-art models now achieve impressive test set performance in the form of accuracy scores. Here, we go beyond this single evaluation metric to examine robustness to semantically-valid alterations to the input data. We identify three factors - insensitivity, polarity and unseen pairs - and compare their impact on three SNLI models under a variety of conditions. Our results demonstrate a number of strengths and weaknesses in the models' ability to generalise to new in-domain instances. In particular, while strong performance is possible on unseen hypernyms, unseen antonyms are more challenging for all the models. More generally, the models suffer from an insensitivity to certain small but semantically significant alterations, and are also often influenced by simple statistical correlations between words and training labels. Overall, we show that evaluations of NLI models can benefit from studying the influence of factors intrinsic to the models or found in the dataset used.
Deep Generative Model for Joint Alignment and Word Representation (Dr. Miguel Ríos Gaona /Universidad de Ámsterdam)
Abstract: This work exploits translation data as a source of semantically relevant learning signal for models of word representation. In particular, we exploit equivalence through translation as a form of distributed context and jointly learn how to embed and align with a deep generative model. Our EmbedAlign model embeds words in their complete observed context and learns by marginalisation of latent lexical alignments. Besides, it embeds words as posterior probability densities, rather than point estimates, which allows us to compare words in context using a measure of overlap between distributions (e.g. KL divergence). We investigate our model's performance on a range of lexical semantics tasks achieving competitive results on several standard benchmarks including natural language inference, paraphrasing, and text similarity.
Ponentes
 Dra. Helena Gómez Adorno
Dra. Helena Gómez Adorno
Investigadora Posdoctoral en el Grupo de Ingeniería Lingüística del Instituto de Ingeniería de la UNAM. Licenciada de la Universidad Nacional de Asunción, Paraguay. Realizó la maestría en ciencias de la computación en la Benemérita Universidad Autónoma de Puebla y obtuvo su doctorado en el Centro de Investigación en Computación del IPN. Realizó estancias de investigación en la Universidad del Egeo (Grecia) y en el Centro de Investigación y Desarrollo de IBM en Alemania. Sus intereses de investigación se encuentran en el área del procesamiento automático del lenguaje. Ha trabajado en sistemas de búsqueda de respuestas, similitud semántica, atribución de autoría y perfilado de autor.

Dr. Ivan Vladimir Meza Ruiz
Investigador asociado del Departamento de Ciencias de la Computación del Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas de la UNAM. Ingeniero por la Facultad de Ingeniería de la UNAM, Maestro y Doctor por la Universidad de Edimburgo. Especializado en la intersección entre el lenguaje humano y la inteligencia artificial. Ha trabajado en sistemas de diálogo, análisis forense del habla, análisis de discurso, traducción automática, robótica y otros. Ha participado en trece proyectos de investigación, autor de más de 60 artículos en congresos, talleres y revistas internacionales. Miembro del Sistema Nacional de Investigadores nivel I.
 Dr. John Arevalo
Dr. John Arevalo
Ph.D. en sistemas y computación de la Universidad Nacional de Colombia. Investigador en el Grupo Machine learning, perception and discovery Lab (Mindlab), y Machine learning specialist para PayU Colombia. Con interés en aprendizaje de la representación y análisis multimodal. Autor de más de 20 publicaciones cientı́ficas en deep learning, análisis de imágenes médicas, procesamiento de lenguaje natural y aprendizaje multimodal.
 Dr. Hiram Calvo
Dr. Hiram Calvo
Hiram Calvo obtuvo el grado de doctor en ciencias de la computación con mención honorífica en 2006 en el Centro de Investigación en Computación (CIC) del Instituto Politécnico Nacional (IPN). Su tesis consistió en un analizador sintáctico de dependencias para el español llamado DILUCT. Obtuvo la Presea Lázaro Cárdenas en 2006. Realizó una estancia postdoctoral de 2008 a 2010 en Nara, Japón, realizando trabajos de análisis de argumentos de una oración con representación distribuida. Desde 2006 es profesor investigador de tiempo completo en el CIC-IPN en el laboratorio de inteligencia artificial. Sus principales intereses son semántica léxica, análisis de texto (perfilado de autor, detección de textos engañosos, clasifiación de emociones), y medidas de semajanza.
 Dr. Fernando Sánchez Vega
Dr. Fernando Sánchez Vega
Dr. Fernando Sánchez-Vega obtuvo el grado de doctorado en ciencias de la computación en el Instituto Nacional de Astrofísica, Óptica y Electrónica (INAOE), Puebla. Es miembro del Laboratorio del Tecnologías del Lenguaje (LabTL), de la Sociedad Española para el Procesamiento del Lenguaje Natural (SEPLN). Ha sido miembro y gestor de proyecto de la Red Temática en Tecnologías del Lenguaje (RedTTL). Ha realizado estancias de colaboración con la Universidad Politécnica de Valencia, la Universidad de Jaén y la Universidad de París XIII y colabora en proyectos de vinculación academia-industria con la Universidad Autónoma Metropolitana, Cuajimalpa (UAM-C) y Winter Genomics A.C. Sus principales intereses son la similitud semántica textual, la detección de plagio, el perfilado e identificación de autor y el análisis de sentimientos en textos.
 Dr. Vicente Iván Sánchez Carmona
Dr. Vicente Iván Sánchez Carmona
Ingeniero en computación por la facultad de ingenieria de la UNAM. Maestro en ingeniería en computación por la UNAM. Doctor por University College London. Mi investigación se centra en análisis de modelos de PLN y de los conjuntos de datos usados para entrenarlos.
 Dr. Miguel Ríos Gaona
Dr. Miguel Ríos Gaona
Ingeniero en sistemas por la Escuela Superior de Computo, IPN. M. en C. del Centro de Investigación en Computación, IPN. PhD, University of Wolverhampton. Postdoc, University of Amsterdam. Intereses: Bayesian Deep Learning, Machine Translation , Recognising Textual Entailment, Semantic Textual Similarity and Word Sense Disambiguation.
Contacto
Comité organizador
- M.C. Gabriela Ramírez de la Rosa (UAM-C)
- Dra. Helena Gómez Adorno (GIL-UNAM)
- Dr. Héctor Jiménez Salazar (UAM-C)
- Dr. Ivan V. Meza Ruiz (IIMAS-UNAM)
- Dr. Hiram Calvo (CIC-IPN)
- Dr. Fernando Sánchez Vega (RedTTL)
- Dr. Esaú Villatoro Tello (UAM-C)
Agradecimientos



